
こんにちはみなさん
何らかのアイテムのフリーワード検索をするとき、従来であれば部分一致検索や全文検索を使って検索しているのではないでしょうか。
部分一致検索や全文検索は、検索語句の全部もしくは一部が含まれていないと、アイテムが抽出対象になりません。
例えば、「魚が食べたい」という文言で検索したとき、名前だけの検索ではマグロやら鯛などの魚すら出てこないでしょうし、その魚の説明文が検索対象に含まれていたとしても、本当に食用魚が出てくるかというと微妙で、「魚」の部分に釣られてバラムツ( 食べてはいけない魚 )なんてものが出てきても困っちゃうわけです( プロダクトが取り扱っているかどうかは別問題ですが )。
より正確な検索をするためには、説明のキーワードを抜き出して、検索語句にピンポイントに当たるようなアイテムを抽出するようにしなければなりませんが、中々難しいです。
そこで、語句自体で検索をすることを諦め、語句やアイテムを一旦コンピューターが扱いやすい形に変換し、新しい検索にチャレンジしたくなるわけです。
今回はこの変換部分をOpenAIに任せ、検索部分のみを実装することで、省力化しつつ類似語検索を実現してみましょう。
何をしたのか
そもそも、どうして類似語検索をする必要が出てきたかということを説明します。
とある機能でユーザーにキーワードを選んでもらうところがあるのですが、選択肢が1000個以上あって、時間の少ないユーザーにこの中から適切なものを選んでもらうのって相当ストレスじゃないかな?という話が出ました。

かといって自由入力にしちゃうと、集計やカテゴライズが不便になってしまうというところで、何とか、選択肢でいきたいわけです。
では、検索をしてキーワードを選んでもらうのかというと、検索語句がキーワードにかすっていないと出てきません。
そこで、ユーザーが入力した検索語句に対し、いい感じの類似後検索で選択可能なキーワードをサジェストする機能を足してやろうということになりました。

単語・文章のembedding
単語や文章を特定次元のベクトルに変換することをembeddingと言います。
なんのこっちゃという感じの方もいるかもしれませんが、簡単にいうと、単語や文章を一定数の数値の組みにしちゃおうという試みです。
例えば 「パン」 という単語を みたいな感じにしちゃうわけです。

ベクトルは一方で矢印として捉えることができるので、2つの単語や文章のベクトルが同じような方向を向いていれば、その二つは類似していると捉えることができます。
変換のやり方はいくつかあって、有名なのだと Word2Vecがあげられますし、OpenAIは文章自体を一つのベクトルに変換するAPIを提供しています。
なぜこんなことができるのかについては後で少しだけ解説できればと思います。
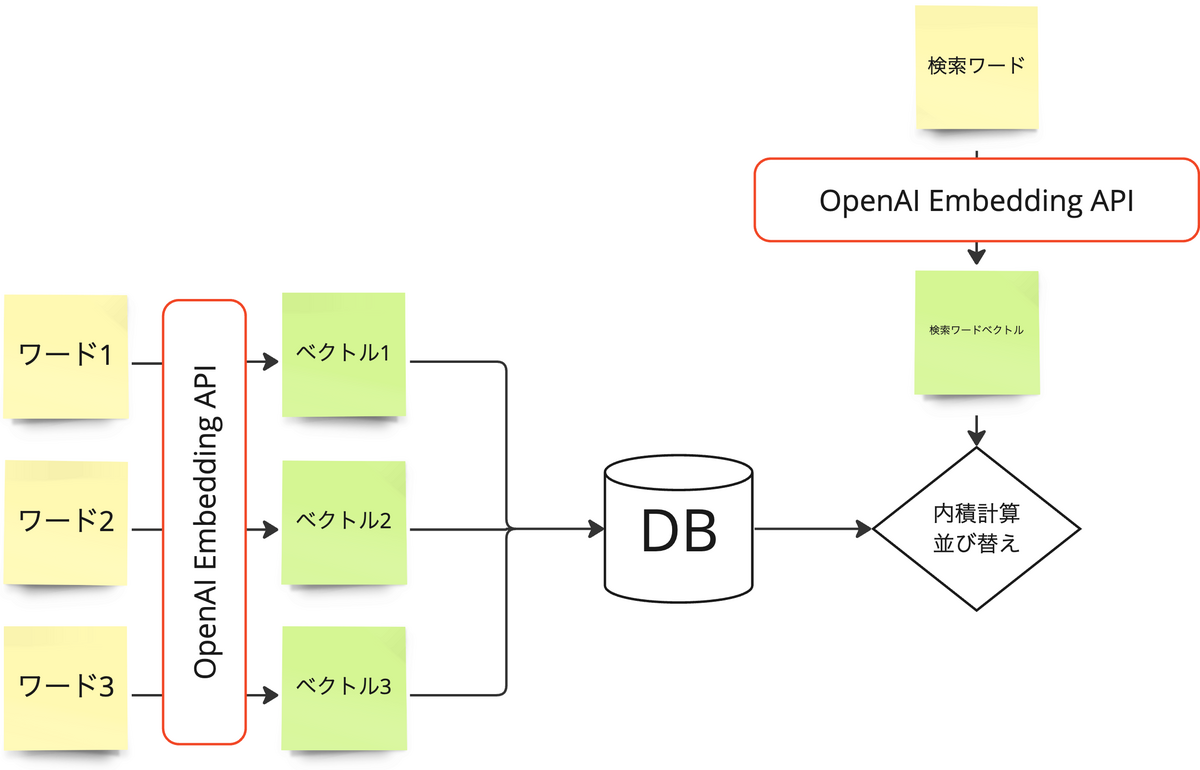
今回弊社では、OpenAIが提供するembedding モデル を利用する1ことで、文章や単語のベクトル化を実現しました。
類似度の算出と並べ替え
ベクトル化はOpenAIに委ねましたが、残りの類似度算出からアイテムの抽出までをプロダクトの中、つまりPHPで実装します。
一般のベクトルの類似度と内積に関する詳しい話は別記事を参照してください。
今回は、検索対象のアイテムをあらかじめembedding APIを使ってベクトル化しておきます。
その上で、入力した検索検索語句をembedding APIでベクトル化し、あらかじめベクトル化した検索対象のアイテムのベクトルとの内積をとります。
embedding APIで生成したベクトルは単位ベクトルですので、内積がそのまま類似度になります。
内積=類似度が算出できれば、あとはその値が大きい順に並び替えます。
本プロダクトでは単純に類似度が高い順に並べた上で、上位の一定数をサジェストする実装にしています。
これをPHPで実装すると以下のようになります。
// 検索語句 $contents = ['蟹味噌']; // 検索語句のベクトル化 // clientはこちらを参照 -> https://github.com/openai-php/client?tab=readme-ov-file#embeddings-resource $client = new Client; $response = $client->embedding($contents); $embedding = $response->toArray()['data'][0]['embedding']; // あらかじめベクトル化していたキーワードとの内積を計算 $rawDotProduct = array_map( fn($item) => [ 'id' => $item['id'], 'keyword' => $item['keyword'], 'dot_product' => dotProduct($item['embedding'], $embedding) ], $keywords ); // 内積の大きい順にソート usort($rawDotProduct, fn($a, $b) => $b['dot_product'] <=> $a['dot_product']); // 結果を出力 // ここでは全部を出力しているが、実際には上澄の一部だけ取り出す foreach ($rawDotProduct as $item) { echo $item['id'] . ': ' . $item['keyword'] . ' ' . $item['dot_product'] . PHP_EOL; }
考察とまとめ
というわけで、OpenAI の embedding APIを利用してベクトル化したキーワードと検索語句を用いて、類似検索を実現したというお話でした。
この類似検索ですが完璧かというとそうでもなく、短いカタカナやひらがなでの検索については結構弱いようで、意味というよりは字面に引っ張られる傾向にありました( パンで調べたところ、「パ」や「ン」が含まれていれば、関係のないと思われるものすら検索できてしまうなど )。
embedding API自体がChatGPTの前処理みたいなものなので、ある程度長い文章でないと距離が計りにくいのかなと思ったりしています。
現在、検索精度の改善のために、以下のような施策を検討しています。
- embedding APIで使用するモデルを変更し、ベクトルの次元を増やすなどして、表現力を向上
- キーワードだけでなく、その説明文などのメタデータを一緒にしてembedding し、そのキーワードに対する解像度を上げた上で、ベクトル化してみる
これらの施策により、より的確な検索結果を提供できると考えています。
今回はこんなところです。
- 弊社では、実際にはAzure OpenAI Serviceを利用してOpenAIの embedding モデルにアクセスしています。↩